Is it time for “Choose Your Own Device” (CYOD)?
I’ve posted over on LinkedIn an article asking the question: “Is it time for Choose Your Own Device?”. Spoiler-alert! I really think it is. Let me know what you think!
Continue ReadingThe voluntary tech guy. Like Batman – but fighting downtime rather than crime.
I’ve posted over on LinkedIn an article asking the question: “Is it time for Choose Your Own Device?”. Spoiler-alert! I really think it is. Let me know what you think!
Continue ReadingUntil writing this, I have made no public reflection on the death of George Floyd, the continuing situation in America (and by extension the UK and so forth), or the trending topic of whether black lives matter. Update: It has come to my attention that there is a subtle but crucially distinct difference between stating […]
Continue ReadingRead my article over at LinkedIn: https://www.linkedin.com/pulse/what-can-technology-delivery-teams-learn-from-spacex-demo-2-hall While watching the Demo-2 SpaceX/NASA launch on Saturday, I started to develop a number of lessons that technology delivery teams can learn from this historical event. I’ve started with 10 lessons, which you can find over on LinkedIn.
Continue Reading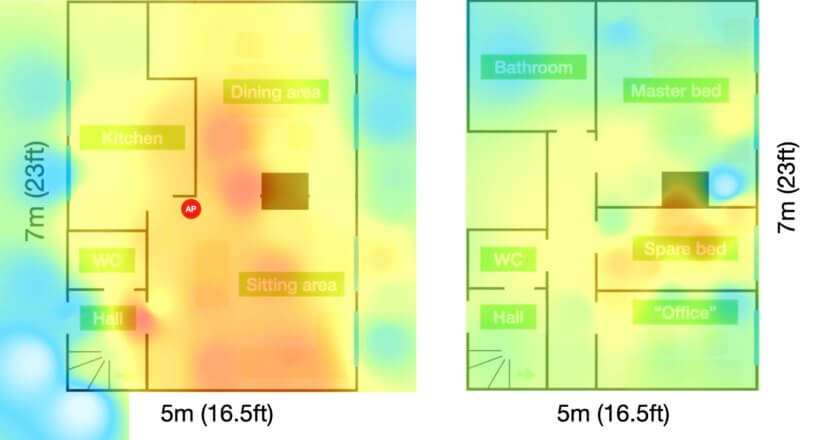
Prologue. So, I finally broke. It was one too many WiFi drop-outs on a day when I just really wanted to be able to watch a TV show without having to fiddle. And I guess that’s where I should start. 10 years ago, our house would be “far from normal”. It’d be modern, edgy, technologically […]
Continue ReadingA few of us today at work discussed the upcoming Apple Watch (pre-orders from 10th April) and the topic of water-proofing came up. A little research on Google reveals no “definitive” answer, so I took matters into my own hands and hunted the main official Apple Watch (web-)pages for any hint. Sure enough I found […]
Continue ReadingThis might be useful to someone, somewhere, out there. Those who’re into tinkering with things they shouldn’t will notice that Ebuyer’s search pages include a “limit” GET variable in the results page URL. The upper limit appears to be 30, but going negatively causes a different kettle of fish: http://www.ebuyer.com/search?q=a%25&x=0&y=0&limit=-3000 (That URL is not for […]
Continue ReadingAye, so the peeps turned up, network coverage is at a minimum, but the weather is good (praise the Lord). Thank you to all those who baked cakes, the chocolate digestive was superb – thanks Elane! Hopefully the campfire pic uploads, hello to all you from East Dean!
Continue ReadingOn that note: I be feeling lucky!
Continue ReadingIf you’re an Essex University student (i.e. you have a valid Essex login) and you’re tired of having to enter campus for access to the Apple Higher Education store, you’ll probably be pleased to know you can do it from home. If you’re running Linux/Unix (including OSX), you’ve already got everything you need. Windows users […]
Continue ReadingFor anyone who claims that IE7 is “the best browser there is” (Davey…), this might just put it in a different light. Goto http://www.plfc.org.uk/ and look at the first link on the page, “FIEC”. Notice (in IE7) that there’s a little gap after it, like there’s a . Well, look at it in FireFox, Opera, […]
Continue Reading